Neo4j + Databricks UC: Federated Query Patterns
This guide demonstrates federated query patterns that combine Neo4j graph data with Databricks Delta lakehouse tables using Unity Catalog. Every query was executed on a live Databricks cluster (Runtime 17.3 LTS) connected to Neo4j Aura and all output shown is actual production output, not mocked data.
What is a Federated Query?
A federated query lets you join data across multiple databases in a single statement without moving the data first. Instead of ETL-ing everything into one system, you query each database where the data already lives and combine the results at read time.
This is particularly powerful when different databases serve different strengths. A graph database like Neo4j excels at modeling relationships and topology such as component hierarchies, flight routes, and maintenance chains. A Delta lakehouse excels at high-volume time-series analytics such as sensor readings, aggregations, and trend analysis over millions of rows. Federated querying lets you combine both in a single analysis without duplicating data or building custom pipelines.
Databricks Lakehouse Federation makes this possible through Unity Catalog (UC). UC acts as a single governance layer that can reach into external databases via JDBC connections, letting you write SQL that spans your lakehouse tables and external sources like Neo4j.
How It Works: Neo4j JDBC + Unity Catalog
The key enabler is the Neo4j JDBC driver with its built-in SQL-to-Cypher translation. When you send a SQL query through a UC JDBC connection, the Neo4j driver automatically translates it to Cypher so Databricks can treat Neo4j as just another SQL data source.
For example, this SQL:
SELECT COUNT(*) AS cnt
FROM Flight f
NATURAL JOIN DEPARTS_FROM r
NATURAL JOIN Airport ais automatically translated by the driver to this Cypher:
MATCH (f:Flight)-[:DEPARTS_FROM]->(a:Airport)
RETURN count(*) AS cntThe UC JDBC connection is created with a CREATE CONNECTION statement that points to your Neo4j instance and loads the JDBC driver JARs from a Unity Catalog Volume:
CREATE CONNECTION neo4j_connection TYPE JDBC
ENVIRONMENT (
java_dependencies '[
"/Volumes/catalog/schema/jars/neo4j-jdbc-full-bundle-6.10.3.jar",
"/Volumes/catalog/schema/jars/neo4j-jdbc-translator-sparkcleaner-6.10.3.jar"
]'
)
OPTIONS (
url 'jdbc:neo4j+s://your-host:7687/neo4j?enableSQLTranslation=true',
user secret('scope', 'neo4j-user'),
password secret('scope', 'neo4j-password'),
driver 'org.neo4j.jdbc.Neo4jDriver',
externalOptionsAllowList 'dbtable,query,customSchema'
)Once this connection exists, you can query Neo4j directly from SQL using remote_query(), or from PySpark using the Spark DataFrame JDBC reader, all governed by Unity Catalog.
The Neo4j JDBC driver requires additional memory for class loading in the Databricks SafeSpark sandbox. Without the correct Spark configuration (spark.databricks.safespark.jdbcSandbox.jvm.maxMetaspace.mib, etc.), the sandbox JVM will crash with "Connection was closed before the operation completed." See the full setup details in the Neo4j UC JDBC Guide.
|
The Demo: Aircraft Digital Twin
To demonstrate federated querying in practice, this guide uses a synthetic aerospace IoT dataset: an aircraft digital twin modeling a fleet of 20 aircraft over 90 days of operations.
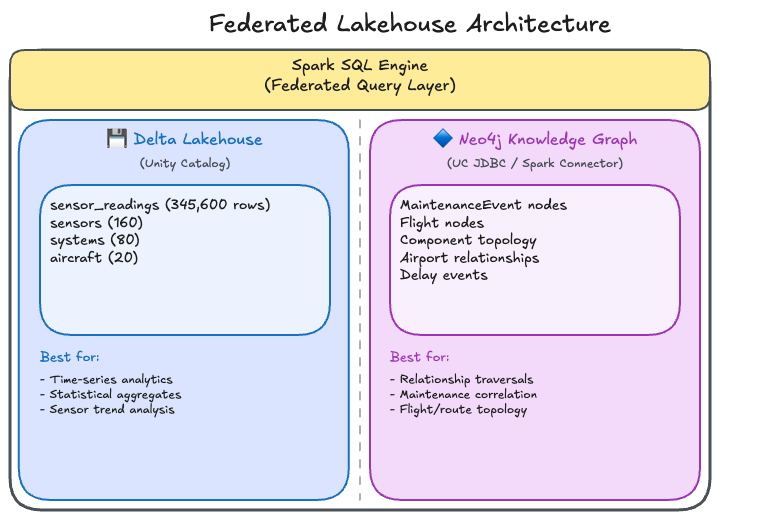
The data is split across two databases, each optimized for what it does best:
| Database | Data | Why |
|---|---|---|
Databricks Delta Lakehouse |
Sensor telemetry (345,600 readings), aircraft metadata, system and sensor catalogs |
High-volume time-series analytics including aggregations, trend analysis, and anomaly detection over millions of rows |
Neo4j Knowledge Graph |
Aircraft, flights (800), airports (12), maintenance events (300), component topology, relationships |
Relationship traversals such as "which flights connect to which airports?", "what maintenance events affect this system?", and component dependency chains |
The federated queries in this guide join both sources to answer questions that neither database could answer alone, for example correlating sensor health trends from the lakehouse with maintenance event patterns from the knowledge graph.
How This Works with Genie
The federated queries shown in this guide can also be driven by natural language through Databricks AI/BI Genie. Instead of writing SQL by hand, a user asks a plain-English question and Genie generates the SQL automatically, federating across Neo4j graph data and Delta lakehouse tables, all governed by Unity Catalog.
The key insight is that Neo4j data can be materialized as managed Delta tables by reading it through the UC JDBC connection and saving the results as regular tables. Once materialized, Genie sees all tables (Delta and Neo4j-sourced) as regular UC tables and generates SQL that JOINs across them transparently.
A Genie space is configured with:
-
Delta tables (direct):
aircraft,systems,sensors,sensor_readings -
Neo4j tables (materialized):
neo4j_maintenance_events,neo4j_flights,neo4j_airports,neo4j_flight_airports -
Instructions: domain context, JOIN patterns, and example SQL that teach Genie how to navigate the sensor data model and cross-source joins
The Genie space can then use natural language queries to query the data, combining Delta tables and Neo4j tables transparently. The full architecture and implementation details are in the Federated Agents guide.
Natural Language → Genie (NL → SQL) → Spark SQL Engine
├── Delta tables → direct read
└── Neo4j tables → materialized via JDBC dbtable + customSchemaFederation Methods
| Method | Pros | Cons |
|---|---|---|
|
Pure SQL, no cluster library, UC governed |
Aggregate-only (no GROUP BY, ORDER BY) |
Spark Connector |
Full Cypher support, row-level data |
Requires cluster library, no UC governance |
UC JDBC: Supported and Unsupported Query Patterns
Spark wraps UC JDBC queries in a subquery for schema inference, which limits what SQL constructs the Neo4j driver can translate. The following patterns were validated against a live Neo4j Aura instance (see the full test results in the Neo4j UC JDBC Guide).
Supported Patterns
All of these passed through UC JDBC with remote_query() or the Spark DataFrame JDBC reader:
| Pattern | Example |
|---|---|
Simple expressions |
|
COUNT, MIN, MAX, SUM, AVG aggregates |
|
Multiple aggregates in one query |
|
COUNT DISTINCT |
|
Aggregates with WHERE (equals, IN, AND, IS NOT NULL) |
|
JOIN with aggregate (graph traversal) |
|
Unsupported Patterns
These patterns fail because Spark’s subquery wrapping conflicts with the Neo4j SQL translator:
| Pattern | Workaround |
|---|---|
|
Use the Neo4j Spark Connector to load row-level data, then aggregate in Spark SQL |
|
Apply sorting and limiting in Spark after the query returns |
|
Use the Spark Connector with Spark SQL filtering |
Non-aggregate |
Use the Neo4j Spark Connector with a Cypher query |
The federated query examples in this guide use remote_query() for aggregate metrics and the Spark Connector for row-level data that requires GROUP BY, combining both methods where needed.
Query Examples
The source for all the examples below is in the federated_lakehouse_query.ipynb notebook. The neo4j-uc-integration repo has more info on setup, configuration, and running the queries end-to-end.
Query 1: Verify Data Sources
Confirm both Delta lakehouse tables and the Neo4j UC JDBC connection are accessible.
Method: remote_query() + Delta SQL
Query 2: Fleet Summary
Fleet-wide overview combining Neo4j graph metrics with Delta sensor analytics in a single SQL statement.
Method: remote_query() with CROSS JOINs
Query 3: Sensor Health + Maintenance Correlation
Per-aircraft correlation of sensor health metrics (EGT, vibration) with maintenance event frequency.
Method: Neo4j Spark Connector → temp view → JOIN with Delta tables
Query 4: Flight Operations + Engine Performance
Aircraft utilization (flight frequency, route coverage) correlated with engine health metrics.
Method: Neo4j Spark Connector → temp view → JOIN with Delta tables
Query 5: Fleet Health Dashboard
Comprehensive fleet health view combining all data sources using both federation methods.
Method: Hybrid using remote_query() + Spark Connector + Delta tables
Query 6: Natural Language Queries with Genie
Query federated Neo4j and Delta lakehouse data using natural language. Genie generates SQL automatically, joining across materialized Neo4j tables and Delta tables through Unity Catalog.
Method: Materialized Neo4j Delta tables + Genie NL-to-SQL
Example Use Cases
Real-world use cases for Neo4j + Databricks Unity Catalog federated queries, including fraud detection, knowledge graph-enriched ML, supply chain visibility, customer 360, and ad hoc exploration.
Deep Dive: UC Integration Setup
How the Neo4j JDBC connection to Unity Catalog was built, including the SafeSpark memory fix, SQL-to-Cypher translation details, the customSchema requirement, validated query patterns, and workarounds for unsupported SQL constructs.
Prerequisites
-
Lakehouse tables in Unity Catalog:
aircraft,systems,sensors,sensor_readings -
Neo4j UC JDBC connection configured (see setup guide)
-
Neo4j Spark Connector installed as cluster library (for queries 3-5)
-
neo4j-uc-credssecret scope configured